3. THE DATABASE
3.1. Database structure
The database was constructed using Microsoft Access software which offers a number of
advantages. It is an extremely powerful relational database tool with excellent
application development. In addition, it is both widely used by other organisations, such
as EUROSTAT, and is able to support a large number of other database formats. Access,
therefore, offers the potential for a great degree of compatibility with other databases
that are already established.
The database is designed to minimise duplication of data and retain flexibility to
allow interrogation for a wide range of queries. Figure 3.1 outlines the major component
data tables held within the database. Four tables hold the information relating to
monitoring required for each directive, these are labelled sampling, core, frequency and
analysis. The information contained in these is as follows:
- Sampling: This table contains general information such as directive name,
reporting frequency and other general comments;
- Core: This contains a list of determinands measured for each directive and
indicates the type of water sampled along with which specific matrix is involved. This
table is the key table in the database structure and provides all of the linking fields
for relating different aspects of data;
- Frequency: Holds data related to frequency and sampling strategy for a
determinand on a determinand basis;
- Analysis: Holds data related to methods of analysis associated with each
determinand and covers all aspects of analytical method and allows comparison of methods
of pre-treatment, limits of detection and AQC procedures.
In the four main tables described above data have been entered as faithfully as
possible to that given in the directives (English versions). This reproduction of
directive requirements has associated problems, small differences in the words used
between one directive and another will mean that the database is incapable of accurately
resolving commonalties. To solve these problems the database holds several look-up tables
which attempt to standardise aspects of the data contained. A clear illustration of this
comes from the determinand look-up table.
| Determinand
described by directive |
Standardised
term for determinand |
| Phenol |
Phenol |
| Phenols |
Phenol |
| Phenolic compounds |
Phenol |
In the above example phenol has been described by different directives in slightly
different ways, the introduction of a standardised term allows the database to readily
assess commonality. By careful consideration look-up tables can be constructed to assess
commonality at any level. For example, the determinand look-up table has been further
extended by grouping determinands into broad categories.
| Determinand described by directive |
Standardised term for determinand |
Broad determinand type |
| Total ammonium |
Ammonia |
Nutrient |
| Non-ionised ammonia |
Ammonia |
Nutrient |
| Ammonia |
Ammonia |
Nutrient |
| Nitrites |
Nitrite |
Nutrient |
| Nitrite |
Nitrite |
Nutrient |
This allows comparison between directives in terms of the types of determinand that are
required for monitoring.

Figure 3.1 Schematic representation of the major elements of the database structure
Information from the directives was categorised in the database in terms of:
1. Water type (using the seven categories stated in the directives):
- surface water (i.e. all types of surface water, namely fresh
surface water, coastal and estuarine waters);
- fresh surface water (i.e. only fresh water, namely rivers,
lakes and reservoirs);
- coastal waters;
- estuaries;
- groundwater;
- freshwater (i.e. fresh surface water and groundwater); or,
- salt water (i.e. coastal and estuarine waters).
2. Matrix:
- water;
- sediment; or,
- biota.
3. Determinand category (quantity and quality):
- physical (river flow, groundwater level, abstraction rate);
- physicochemical (pH, salinity, alkalinity, temperature,
turbidity, suspended solids);
- organic pollution indicators (dissolved oxygen (DO),
biochemical oxygen demand (BOD), chemical oxygen demand (COD), organic carbon, redox
potential);
- metals;
- synthetic organic compounds (e.g. organochlorines,
organophosphorus, PAHs);
- nutrients (nitrogen, phosphorus);
- microbiological (total coliforms, faecal coliforms, faecal
streptococci, viruses);
- biological (invertebrates, fish tissue, shellfish, algae);
- radioactivity (gross alpha and beta radioactivity, specific
radionuclides);
- chemical (other than physicochemical, organic, nutrients or
metals); or,
- aesthetic (foam, mineral oils, surfactants).
4. Sampling
- methodology (e.g. on-line, discrete, composite);
- frequency; or,
- location and density.
5. Analysis
- storage and pre-treatment;
- methods;
- performance; or,
- specified quality control procedures.
6. Reporting
- data treatment;
- data storage;
- compliance assessment of data against, for example,
relevant standards and other requirements; or,
- data availability, exchange and reporting.
An identical database was constructed for the international agreements. This allowed
comparison of directives and international agreements at any level of detail either,
within the databases, or through other packages such as Microsoft Excel.
3.2. Data analysis
Much of the analysis of the database has been undertaken using graphical-descriptions
of the relationships between the monitoring requirements in the various directives. This
has the aim of reducing the complexity of the multivariate information to a
low-dimensional picture of how the directives may interrelate. The two techniques
exploited here are hierarchical clustering and non-parametric multi-dimensional scaling
(MDS). Each of these methods start explicitly from a triangular matrix of similarity
coefficients computed between every pair of directives. This coefficient is a simple
algebraic measure of how close the directives are, for example if two directives required
monitoring of exactly the same determinands they would be 100% similar at this level.
Following the calculation of the similarity matrix, the results can be represented by a
dendogram, linking the samples in hierarchical groups on the basis of the similarity
between each cluster, or using MDS which attempts to place directives on a map. Both of
these methods give a visual representation of "closeness" of the monitoring
requirements of any combination of directives, Figure 3.2 outlines the stages involved the
multivariate analysis.
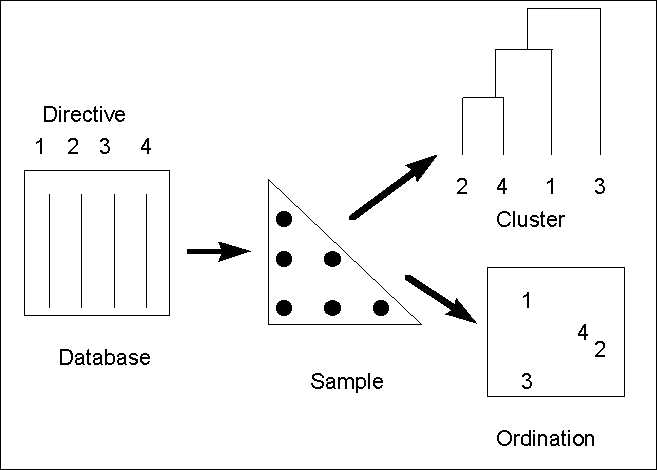
Figure 3.2 Stages in multivariate analysis (adapted
from Clarke and Warwick 1994)


Document Actions
Share with others